Faits & entités : quels liens avec le SEO ?
Les années passent et le SEO continue son évolution. À en croire Google, si le domaine est en permanente mutation, c’est pour mieux valoriser les contenus de qualité. Facile à dire, mais assez compliqué à concrétiser quand on s’y intéresse de plus près. Une chose est sûre : les liens entre le Knowledge Graph, les faits et les entités se renforcent pour apporter une réponse toujours plus pertinente et précise aux internautes. Mais comment ça fonctionne exactement ? Quels sont les intérêts et les impacts des faits et des entités en SEO ?
Du mot-clé à l’entité… et aux faits
Tous les spécialistes du SEO ont un jour été amenés à travailler sur une étude de mots-clés, également appelée audit sémantique ou identification des réservoirs d’audience. Ce dernier nom est d’ailleurs celui que l’on privilégie chez l’agence WAM, car il se détache de la notion de mot-clé. Il évoque un concept plus large que le simple mot.
Pour mener à bien ce travail, on utilise encore largement Excel (ou Google Sheets). On liste dans le tableau des expressions auxquelles sont rattachés habituellement :
- un volume de demandes estimé ;
- une position ;
- une URL ;
- des fonctionnalités de SERP (images, vidéos, local pack) ;
- une thématique ;
- une intention ;
- etc.
Ces éléments constituent la matière première dont le SEO va tirer des informations pertinentes. Le but est de définir une stratégie de visibilité visant à répondre à une question vaste mais primordiale : comment faire pour atteindre l’objectif que l’on s’est fixé ?
Laissée à l’état brut, cette matière première ne servira pas à grand chose. Elle pourra poser les bases d’un plan de publication alimentant une stratégie de contenus ou servir de moyen de pression rudimentaire auprès des rédacteurs pour optimiser leurs articles.
Pour transformer ce minerai en pierre précieuse, le secret, c’est d’apporter du sens aux expressions que l’on travaille. Cela facilite la compréhension des mots : on ne travaille alors plus simplement sur les termes, mais sur leur signification réelle.

Le travail sur la signification des expressions va aussi faciliter la tâche des rédacteurs, qui perçoivent mieux les sujets en lien avec celui qu’ils sont en train de traiter. Le maillage interne devient ainsi plus simple : on peut relier des thèmes, sujets ou entités entre eux et donner vie à ce réseau de sens via des liens html. Et pour relier des entités entre elles, le meilleur moyen, c’est d’utiliser des faits. La preuve par l’exemple :
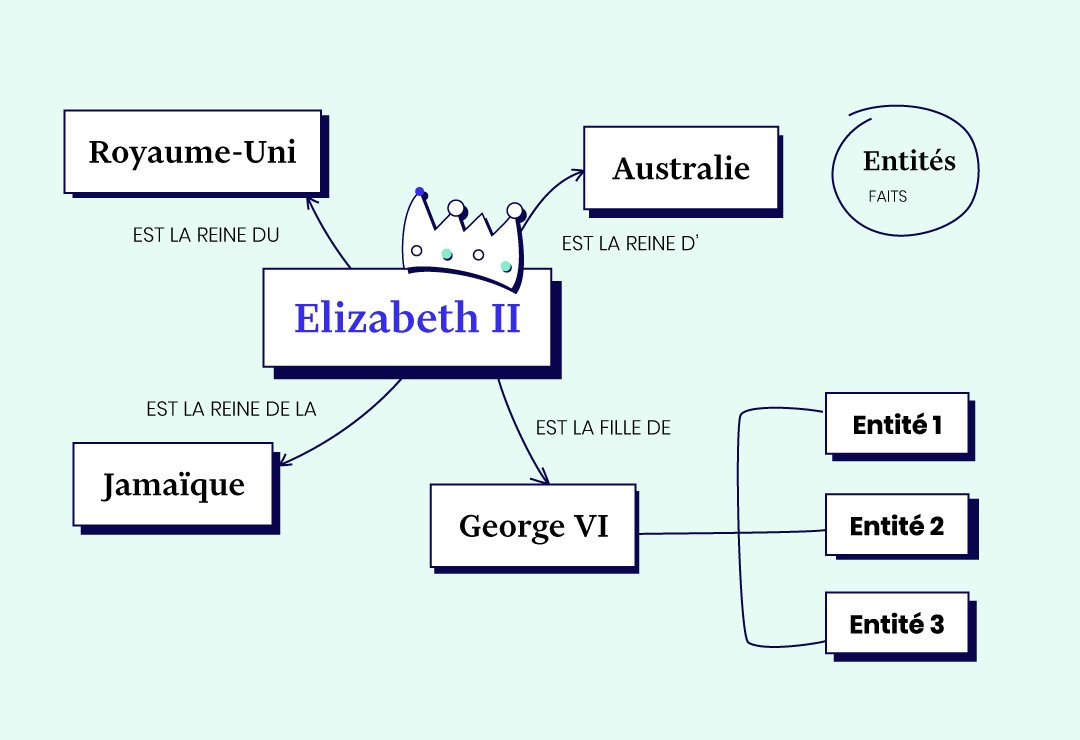
En appliquant cette logique à son travail sur le SEO, on gagne en pertinence et on trouve de nouvelles manières de présenter les contenus. Ce qui n’est pas sans rappeler le Knowledge Graph.
Et le graph de connaissances de Google dans tout ça ?
Imaginons tous les faits qui peuvent être reliés à une entité comme Elizabeth II. On touche alors du doigt ce que Google construit depuis tant d’années : une immense base de données qui regroupe toutes les entités et les faits qui constituent notre monde. D’ailleurs, un aperçu de ce fonctionnement est déjà en place dans les SERP, lorsque l’on interroge Google sur un fait.
Google se perfectionne avec MUM et LaMDA
Google MUM et LaMDA, présentées au Google I/O 2021, sont des technologies qui aident Google à se transformer, quittant son statut de moteur de recherche pour devenir un moteur de réponse. Il se rapproche ainsi de plus en plus de son objectif final : devenir un assistant personnel incollable sur tout.
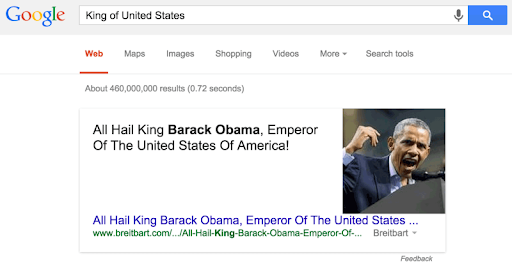
Mais le chemin est encore long et la fiabilité reste le principal point de blocage qui empêche Google d’achever sa mue. En effet, le graph de connaissances comporte certains biais, faux-pas et erreurs qui peuvent nuire à la pertinence de Google. Cela a été le cas il y a quelques années, avec Barack Obama présenté comme le roi des États-Unis.
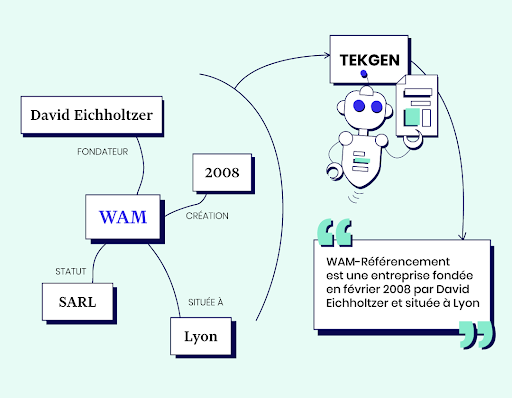
Le rôle de TeKGen et KELM pour améliorer l’exactitude factuelle
Cette fiabilité, au delà de son travail réalisé avec BERT sur la compréhension du langage, le moteur de recherche la travaille à travers TeKGen et KELM, qui vérifient les informations servies par le web en les comparant à son graph de connaissances. On part d’entités et de faits nomenclaturés et de données structurées, qui permettent de construire des phrases sur la base du NLP (Natural Language Processing). De quoi en faire une véritable interface homme/machine qui peut nous parler sans qu’on la prenne pour un simple robot.
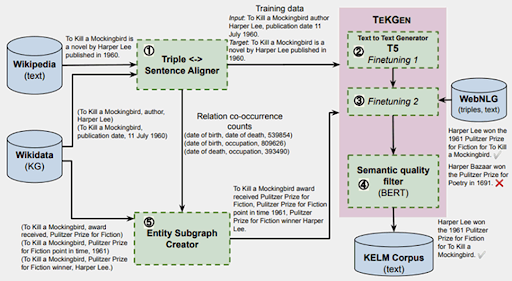
Ce schéma illustre la façon dont Google travaille avec TeKGen et KELM pour réduire les biais dans la fiabilité des contenus autogénérés sur la base de son Knowledge Graph.
Pour résumer, voici les principales étapes :
- Les données texte de Wikipédia et les données nomenclaturées de Wikidata sont fusionnées pour générer une première version de l’information.
- Le texte est généré une première fois via la solution de génération de contenu T5.
- Le texte s’enrichit ensuite avec une notion de NLG (Génération de langage naturel) et des informations provenant de l’étape 5.
- BERT est utilisé pour améliorer la qualité de la phrase de sortie.
- Les entités liées au sujet sont utilisées pour alimenter en informations la phrase générée après l’étape 4.

Quelles sont les implications des faits et entités sur le travail SEO ?
Autorité, contextualisation de vos contenus, structuration des données : afin de faire de votre marque une entité reconnue par Google, différents leviers peuvent être actionnés.
Un travail de l’autorité de votre marque
Une des missions clés de vos équipes marketing et communication consiste à placer votre marque au cœur de ce processus. L’objectif est de faire de votre marque une entité à part entière, connue et reconnue sur votre marché, en la reliant à celles déjà existantes par des faits.
Vous pouvez par exemple vous servir des RP pour générer un baromètre récurrent sur votre marché. Il sera ensuite diffusé et partagé par d’autres entités et finira par être relié à votre marque dans le graph de connaissances de Google.
Il sera également plus simple pour vous d’ajouter du contenu sur Wikipédia en citant des sources qui vous mentionnent. Sans cela, difficile d’y figurer sans se faire rattraper par des modérateurs trop pointilleux.
Un travail à opérer sur vos contenus
Autre piste, peut-être plus simple et accessible à tous : insérer des mentions d’entités reliées à votre marché lors de la création de vos pages ou contenus.
Bien entendu, cela doit être fait uniquement lorsque c’est pertinent. Le but est de permettre à Google de comprendre que votre site fait partie d’un ensemble, qu’il fait appel à des ressources présentées ailleurs.
Présenter des références à des entités que Google peut déjà connaître en partie de son côté ne vous rendra pas meilleur. Cela aidera à « valider » la pertinence de votre contenu lorsque vous en faites mention (selon la manière dont c’est fait).
Si vous citez une étude de référence sur un sujet ou les propos d’un auteur reconnu de votre secteur, par exemple, Google pourra relier le reste de votre contenu à une base qu’il connait déjà.
Un travail des données structurées schema.org
Dernier point qu’il peut être utile de traiter : l’encodage via schema.org de l’entité relative au contenu de votre page.
Ici, rien de bien compliqué : il faut identifier l’entité concernée et se rendre sur schema.org pour structurer votre donnée avant implémentation dans vos pages.
Articles relatifs
Voir tous nos articles-

Comment générer du trafic sur Google Discover ?
15 minutes
-
Helpful Content : et si Google avait trouvé le moyen d’évaluer l’expérience de vos contenus ?
15 minutes
-
Et si c’était la fin des mots-clés dans la recherche Google ?
11 minutes
-
SEO & UX : Comment agir sur l’engagement des utilisateurs dès la SERP ?
15 minutes




Restons connectés
Dites-nous ce que l’on peut faire pour vous !
Parce qu’une vraie discussion vaut mille briefs PDF, contactez-nous pour échanger de vive voix sur votre autorité digitale, vos besoins, votre projet. Mieux ? Venez nous voir en vrai dans notre agence à Lyon ou à Mulhouse.